Back to 2024 Posters
VQI Vein Module Data Entry can be Accurately Completed by Generative AI
Benjamin C Ford, Kathleen Fear, Michael J Hasselberg, Jennifer Ellis, Stacey Esposito, Michael C Stoner
University of Rochester, Rochester, NY
BACKGROUND: The Vascular Quality Initiative (VQI) has emerged as a powerful tool for research and quality improvement. However, countless work hours are required for data entry. The rise of generative artificial intelligence (AI) and large language models (LLM) offers an avenue to decrease the time spent by humans on data entry, thus decreasing costs and freeing personnel for other projects. Here we describe the use of a LLM to augment the extraction of data from unstructured notes for the varicose vein module of the VQI.
METHODS:We utilized OpenAI’s GPT-4 model via an API connection in a secure Azure tenant. Pre-operative, operative and post-operative note text was extracted from the electronic health record. For the initial model, GPT-4 was presented with a prompt constructed from the text of all three notes along with the varicose vein module data dictionary. A second set of prompts were developed to improve accuracy by splitting the extraction into stages: first presenting the operative note and registry elements for the procedure, followed by the preoperative note and history/current status elements, and finally the post-operative note and associated elements. This model was used to extract data for 320 cases that had been completed in January - July 2024. The accuracy of the LLM extracted data was validated against the data collection forms filled out by chart data abstraction team.
RESULTS:The initial approach was 59% accurate across a test set of 20 patients. Most inaccuracies were from inappropriate inclusion of the contralateral limb. The second approach identified the procedure’s laterality from the operative note and carried that information forward when reading the preoperative and postoperative notes to ensure appropriate laterality. This adjustment improved the accuracy of the data for our test patient set to 95%. (Table) We then ran the second approach on our full validation cohort of 320 patients, resulting 93% accuracy overall, and >90% accuracy for 235 cases (Figure). The accuracy for the remaining 85 cases ranged from 79-89%. The majority of these inaccuracies were again from incorrect laterality chosen by the model or incorrect listing of pre-operative symptoms. The average extraction time per case was 45 seconds, compared to 30 minutes for data entry staff to complete the same data collection form, a 4000% efficiency increase.
CONCLUSIONS: This study shows that LLMs can significantly reduce the amount of time required for data entry to VQI. Improvements with the second LLM model demonstrate the importance of operational order when working with GPT-4. The addition of human auditing of the data will provide an optimal solution to ensuring accuracy and decreasing data entry time.
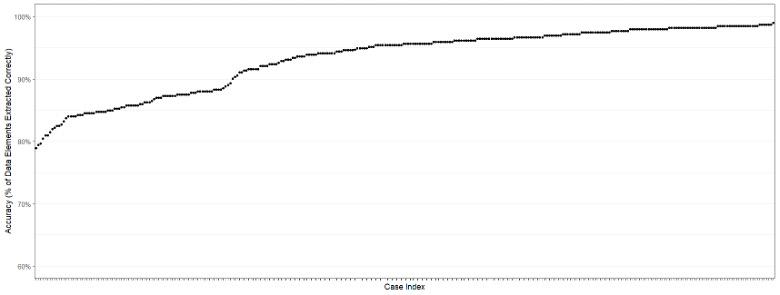
Figure: Percent Data Elements Extracted Accurately per Case (320 cases)
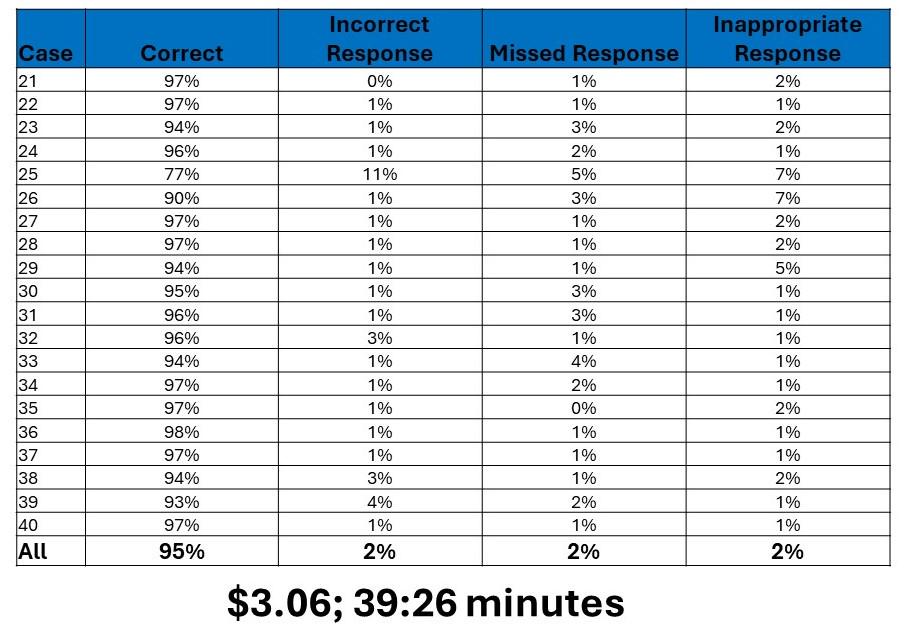
Table: Accuracy, Cost, and Time for Second Approach on Twenty Cases
Back to 2024 Posters


